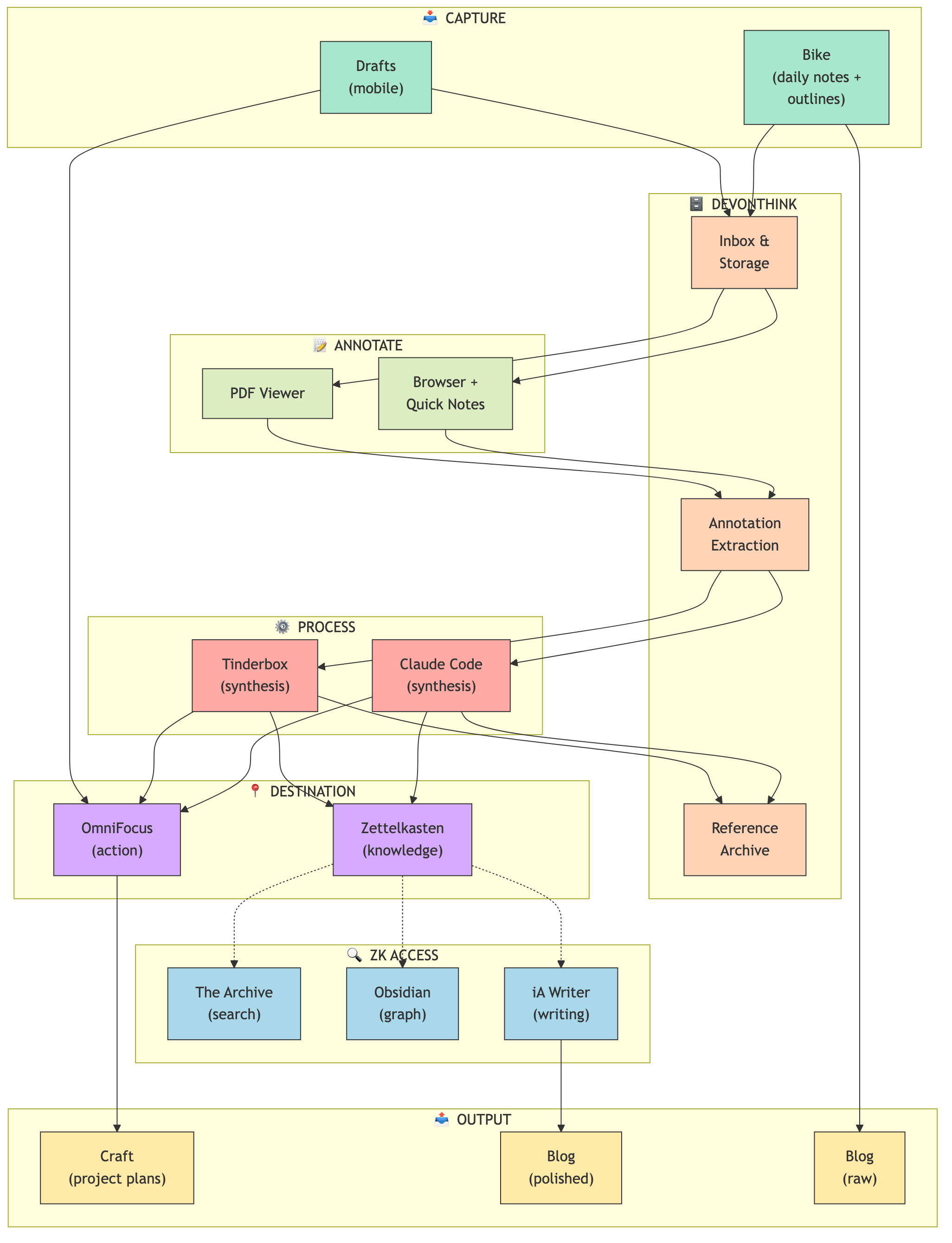
I’ve built a homegrown incremental reading system that spans multiple apps. It’s not SuperMemo, and that’s intentional. I want zettelkasten notes, not flashcards.
The core idea
I’m interested in acquiring knowledge, not memorizing every detail of it (2025-01-25_10-52). The zettelkasten lets me lazy-load information by following links and running into notes accidentally. SuperMemo’s spaced repetition is about remembering concepts, so you don’t get that “external conversation partner” feeling.
Reading, for me, is filtering. I’m mining articles for 2-3 good ideas, then moving on. Most content is noise anyway.
How capture works
Readwise Reader has a great parser, so I use it for saving articles. A syncer pulls them into both Craft (where the content lives) and OmniFocus (where the queue lives, with AI-assigned priorities from 1-9).
I also capture manually via OmniFocus Quick Capture for random URLs and Safari Reading List stuff, plus DEVONthink automation for documents.
Everything ends up in the same @Read/Review perspective in OmniFocus.
The queue
OmniFocus handles scheduling, not content. The actual reading material stays where it belongs: articles in Craft, documents in DEVONthink, web pages in Safari, notes in my zettelkasten.
I use an Adaptive Task Repetition plugin (CMD-Shift-I) that works like SM-2. When I process an item, I rate how well it went: Again, Hard, Good, Easy, or Completed. The interval multiplies accordingly (1.4x for Hard, 2.0x for Good, 2.5x for Easy). Items I don’t care about, I just delete.
The queue has three workflow states: Discuss, Distill, and Synthesize.
Two-phase processing
2.6.5.3.2 formalizes something I realized: distillation and synthesis are different cognitive modes. Mixing them is exhausting.
Distill is understanding mode. I scan an article, bail if it’s not interesting, otherwise read and highlight. Maybe repeat it tomorrow, adjust the priority. I get about 0.75 extracts per article, which sounds low but most articles just don’t have that many good ideas.
Synthesize is creation mode. I review my timestamped notes, connect them to existing ideas, and when one is ready, I add the #Linking tag and rename it to folgezettel format (like 2.3.4) to place it in the outline.
The separation reduces cognitive load. I’m not trying to understand AND create at the same time.
The funnel
World (infinite)
↓ Readwise/manual capture
↓ AI priority [1-9]
↓ Spaced repetition scheduling
↓ Distill
↓ Synthesize
Zettelkasten
Each step reduces volume and increases value. Most articles die in the funnel. That’s the point.
Output expectations
I produce about 164 timestamped notes per year, and roughly 30 of those become folgezettels (about 18% conversion). The rest stay as timestamped notes, which is fine. They’re composting, not stuck. Some never mature, some resurface years later and become important.
Constraints
This is cognitive work, not leisure. I can only do it at the end of the day when I have energy, or maybe once or twice on weekends. Sometimes I just don’t give a fuck and pick something from Safari Reading List instead.
Output is limited by attention, not system mechanics. About 3-5 sessions per week, and the system performs at the capacity I give it.
How this differs from SuperMemo
SuperMemo fragments articles early into many small pieces, then schedules each fragment separately. The goal is memorization via QA cards.
I fragment late, at the natural reading moment. The goal is zettelkasten notes that connect ideas. Article-level granularity makes more sense for this.
2.19 notes that incremental reading extracts are efficient but disruptive for stories. The fragmented approach doesn’t suit all content types, and I prefer reading articles whole until I’m ready to extract.
- 2.6.5.3.2 Splitting information extraction into distillation and synthesis
- 2.19 Incremental reading extracts are efficient but disruptive for stories
- 2025-01-25_10-52 The Zettelkasten is for people who want to lazy-load knowledge
- 2025-01-20_22-25 The extraction is a key collection workflow
- 2025-01-19_13-40 Literature Notes, Where do they go once they become Permanent Notes?